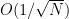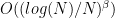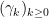Published on arxiv:
Improving reinforcement learning algorithms: towards optimal learning rate policies
Abstract: This paper investigates to what extent we can improve reinforcement learning algorithms. Our study is split in three parts. First, our analysis shows that the classical asymptotic convergence rate