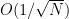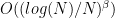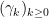Congratulations to Blanka Horvath, Aitor Muguruza and Mehdi Tomas for the award ( Risk Awards 2020: The winners ) based on the paper Deep Learning Volatility ). More details at Risk.
Month: November 2019
Improving reinforcement learning algorithms: towards optimal learning rate policies
Published on arxiv:
Improving reinforcement learning algorithms: towards optimal learning rate policies
Abstract: This paper investigates to what extent we can improve reinforcement learning algorithms. Our study is split in three parts. First, our analysis shows that the classical asymptotic convergence rate